使用Rust编写操作系统 - 3.1 - 内存分页简介
在这篇文章中,我们将介绍分页机制,这是一种非常常见的内存管理方案,我们还将会在操作系统中实现它。本文还将解释为什么需要内存隔离、分段如何工作、什么是虚拟内存以及分页如何解决内存分段问题。此外,还探讨了x86_64架构上的多级页表的布局。
这个博客是在GitHub上公开开发的。如果你有任何问题或疑问,请在那里开一个issue。你也可以在底部留言。这篇文章的完整源代码可以在post-08分支中找到。
内存保护
操作系统的一项主要任务是将程序彼此隔离。例如,你的网络浏览器不应该干扰你的文本编辑器。为了实现此目标,操作系统利用硬件功能来确保一个进程的内存区域不能被其他进程访问。内存保护有多种的方法,具体取决于硬件和操作系统实现。
例如,某些ARM Cortex-M处理器(用于嵌入式系统)具有内存保护单元(MPU),可让用户定义少量(例如8个)具有不同访问权限(例如,无权访问、只读、读写等)的内存区域。在每次内存访问中,MPU会确保该地址位于具有正确访问权限的区域中,否则将抛出异常。通过在每次进程切换时更改区域和访问权限,操作系统可以确保每个进程仅访问它自己的内存,从而使进程彼此隔离。
内存分段
分段早在1978年就已出现,最初是为了增加可寻址内存的数量。当时的情况是CPU仅使用16位地址,这将可寻址内存量限制在了64KiB。为了能够访问大于64KiB的内存,于是引入了附加的段寄存器,每个段寄存器都包含一个偏移地址。CPU会在每次访问内存时自动添加此偏移量,从而使可访问内存最多增加到1MiB。
CPU会根据内存访问的类型自动选择不同的段寄存器:对于获取指令,将使用代码段CS;对于栈操作(压栈/弹栈),将使用栈段SS。其他指令使用数据段DS或额外段ES。之后又添加了两个额外的段寄存器FS和GS,可供自由使用。
在内存分段的首个版本中,段寄存器直接包含偏移量,而且也不进行访问控制。这一点后来随着保护模式的引入而改变。当CPU在该模式下运行时,段描述符包含访问本地或全局描述符表的索引,该表除偏移地址外还包含段大小和访问权限。通过为每个进程加载单独的全局/本地描述符表,从而将对内存的访问限制在该进程自己的内存区域,操作系统也因此能够将进程彼此隔离。
通过在实际访问之前修改内存地址,内存分段也不知不觉的引入了一种在今天几乎到处使用的技术:虚拟内存。
虚拟内存
虚拟内存的思路是将内存地址从底层物理存储设备中抽象出来。不同于直接访问存储设备,这里会先执行一个转换步骤。对于内存分段,转换步骤是添加活动分段中的偏移地址。假设一个程序在偏移量为0x1111000的段中访问内存地址0x1234000:实际访问的地址为0x2345000。
为了区分这两种地址类型,转换前的地址称为虚拟地址,转换后的地址称为物理地址。这两种地址之间的一个重要区别是物理地址是唯一的,相同的物理地址始终指向相同且确定的内存空间。而虚拟地址则取决于转换。两个完全不同的虚拟地址可能指向相同的物理地址。同样,当相同的虚拟地址使用不同的转换时,它们可以指向不同的物理地址。
举个例子:并行执行同一个程序两次,就可以很好的解释这一行为:

例子中的同一程序运行两次,但具有不同的转换。第一个实例的段偏移量为100,因此其虚拟地址0–150转换为物理地址100–250。而第二个实例的偏移量为300,它将其虚拟地址0–150转换为物理地址300–450。这使两个程序都可以运行相同的代码并使用相同的虚拟地址,而不会互相干扰。
另一个优点是,即使程序使用完全不同的虚拟地址,现在也可以将它们放置在任意期望的物理内存中。因此,OS可以利用全部的可用内存,而无需重新编译程序。
内存碎片
内存分段强大的地方就在于虚拟地址和物理地址之间的区别。但是,它也具有碎片化的问题。例如,假设我们要运行上面看到的程序的第三份副本:

虽然仍有足够的可用内存空间,但我们也无法在不覆盖前两个实例的情况下,将程序的第三个实例映射到虚拟内存。问题在于,内存分段需要连续的内存,而不能有效利用小的空闲块。
解决这种碎片的一种方法是暂停执行,将内存中已使用的部分移到更近的位置,更新转换偏移量,然后恢复执行:

现在就有足够的连续空间来启动程序的第三个实例了。
这种碎片整理过程的缺点是需要复制大量内存,从而降低了性能。还需要定期进行整理,以免造成内存碎片过多。由于程序在随机时间暂停并且可能变得无响应,因此这使得系统行为不可预测。
这些问题是大多数系统不再使用内存分段的原因之一。实际上,x86上的64位模式甚至都不再支持分段,而是使用分页,这可以完全避免碎片问题。
内存分页
这个思路是将虚拟和物理内存空间都分成固定大小的小块。虚拟内存空间的块称为页,物理地址空间的块称为帧。每个页可以单独映射到一个帧,这使得我们可以在不连续的物理帧之间划出更大的内存区域。
如果我们回顾一下碎片化内存空间的例子,而这次使用分页而不是分段,就可以看到这样做的优点:

上图中的页面大小为50字节,这意味着我们的每个内存区域都分为三个页面。每个页面分别映射到一个帧,因此连续的虚拟内存区域可以映射到非连续的物理帧。这使我们可以在不执行任何碎片整理的情况下启动程序的第三个实例。
潜在碎片
与分段相比,分页使用许多固定大小的小块内存区域,而不是一些可变大小的大块区域。由于每个帧都具有相同的大小,因此不会存在太小而无法使用的帧,也就不会发生碎片了。
这样做看起来似乎没有碎片。不过确实仍存在着某些潜在碎片,即所谓的内部碎片。发生内部碎片是因为并非每个内存区域都正好是页面大小的整数倍。想象一下在上面的示例中,一个大小为101的程序:它仍将需要三个大小为50的页面,也就是比程序所需多占了49个字节。为了区分两种类型的碎片,使用分段时发生的碎片类型称为外部碎片。
内部碎片是不好,但通常要好于分段时发生的外部碎片。它仍然会浪费内存,不过好在不需要碎片整理,并使碎片量可预测(平均每个内存区域约半页)。
页表
可以看到这数以百万计的页面中的每一个都可以映射到一个单独的帧,而这套映射信息应当被记录在某处。内存分段为每个活动内存区域配置了一个单独的段选择器寄存器,这显然不能用于分页,因为页面数量远多于寄存器。相反,分页使用称为页表的表结构来记录映射信息。
对于我们上面的例子,页表如下所示:

我们看到每个程序实例都有自己的页表。指向当前活动页表的指针存储在特殊的CPU寄存器中。在x86上,此寄存器称为CR3。 在运行每个程序实例之前,操作系统的工作是将指向正确页表的指针加载到该寄存器。
在每次访问存储器时,CPU将会从寄存器读取页表指针,并为被访问页面查找其对应的映射帧。这个过程完全由硬件完成,且对运行中的程序完全透明。为了加快转换过程,许多CPU架构都有一个特殊的缓存,用以记住上一次转换的结果。
对于一些硬件架构,页表条目还可以存储诸如访问权限一类的标志字段属性。在上面的示例中,具有“r/w”标志说明页面可读可写。
多级页表
我们刚刚看到的简单页表在较大的地址空间中存在一个问题:浪费内存。例如,假设有一个程序使用四个虚拟页面0、1_000_000、1_000_050和1_000_100(_为千位分隔符):

它仅需要4个物理帧,但是页表有超过一百万个条目。我们不能省略空条目,因为如果省略空条目,翻译过程就无法继续保证CPU能够直接跳转到正确的条目了(例如,并不能保证第四页使用第四个条目。译注:翻译过程应保证低计算复杂度,如O(1),因为几乎所欲操作都会涉及内存页表,所以保证CPU能够直接跳转非常重要。)。
为了减少浪费的内存,我们可以使用两级页表。思路是我们对不同的地址区域使用不同的页表。另一个称为2级页表的额外表包含了地址区域和(1级)页表之间的映射。
最好用一个例子来解释。让我们定义每个1级页面表负责一个大小为10_000的区域。对于上面的例子,则有下表:

第0页属于前10_000字节区域,因此它将使用2级页表的第一个条目。此条目指向1级页表T1,该页表指出第0页指向第0帧。
页1_000_000、1_000_050和1_000_100都属于第100个10_000字节区域,因此它们使用了2级页表的第100个条目。该条目指向另一个1级页表T2,该表将这三个页面分布映射到第100、150和200帧。注意,在1级表中的页面地址不包括区域偏移量,因此页面1_000_050在1级页表中的条目应为50。
虽然在2级表中仍有100个空条目,但比以前的百万个空条目要少得多。节约的空间就在于,我们并不需要为从10_000到1_000_000之间的未映射内存区域创建1级页表。
两级页表的原理可以扩展到三级、四级或更多级。然后,页表寄存器指向最高级的表,该表指向下一个较低级的表,再指向下一个较低级的表,依此类推。最后,1级页表指向映射的帧。通常,该原理称为多级页表或分层页表。
现在我们知道分页和多级页表是如何工作的,接下来可以看看x86_64架构中的分页是如何实现的(后文假设CPU在64位模式下运行)。
x86_64的分页
x86_64架构使用4级页面表,每个页面大小为4KiB。每个页表无论层级,均为具有512个条目的固定大小。每个条目的大小为8个字节,因此每个表的大小为512 * 8B = 4KiB,也正好为一页。
每级的页表索引能够直接用虚拟地址算出:

每个表索引有9位,因为每个表都有2^9=512个条目。最低的12位是4KiB页中的偏移量(2^12字节=4KiB)。第48到64位将被忽略,可以看出x86_64其实并不是真正的64位,因为它仅支持48位地址。
即使第48至64位将被忽略,也不能将这些位设为任意值。而是将这些位都赋上第位47的值,以保持地址唯一,并允许将来的扩展(如5级页表)。这被称为符号扩展,因为它与二进制补码中的符号扩展非常相似。如果地址未正确进行符号扩展,会引发CPU异常。
值得注意的是,最近Intel的“Ice Lake” CPU可选地支持5级页表,并将虚拟地址从48位扩展到57位。在当前阶段,为特定CPU优化我们的内核没有意义,因此本文仅使用标准的4级页表。
地址转换示例
让我们看一个例子,以详细了解转换过程的原理:

当前活动的4级页表的物理地址,也就是该4级页表的根,存放在CR3寄存器中。然后,每个页表条目都指向下一级表的物理帧。最后,1级页表的条目指向地址映射的帧。请注意,页表中的所有地址都是物理地址,而不是虚拟地址,否则CPU也需要转换这些地址(而这可能导致无限递归)。
上面的页面表层次结构映射了两个页面(蓝色)。从页表索引中,我们可以推断出这两个页的虚拟地址为0x803FE7F000和0x803FE00000。现在,让我们看看当程序尝试读取地址0x803FE7F5CE时会发生什么。首先,我们将地址转换为二进制,并确定该地址的页表索引和页偏移量:

有了这些索引,我们现在可以遍历页表层次,确定该地址映射的物流帧:
- 我们首先从
CR3寄存器中读取第4级页表地址。 - 4级页表索引为1,于是我们查看表中索引为1的条目,该条目告诉我们3级页表存储在地址16KiB中。
- 我们从该地址加载3级表,然后查看索引为0的条目,该条目告诉我们2级页表存储在地址24KiB中。
- 2级页表的索引为511,于是我们查看该表的最后一个条目,以查找1级表的地址。
- 通过1级页表中索引为127的条目,最终找到页面映射到12KiB帧,即十六进制的0x3000。
- 最后一步,将页面偏移量添加到帧地址上,获取的物理地址为0x3000 + 0x5ce = 0x35ce。

1级页表中页面的权限为r,即只读。硬件会强制执行这些权限,如果我们尝试对该页面写入,将会引发异常。较高级别页面中的权限限制了较低级别中的可能权限,因此,如果我们将3级页面条目设置为只读,则即使较低级页面指定了读/写权限,使用该条目的页面也将无法执行写入。
需要注意,此示例使用了每级表仅有单个实例,但在实际中,通常地址空间中的每级表都有多个实例。最多有:
- 一个4级页表,
- 512个3级表(因为4级表有512个条目),
- 512 * 512个2级表(因为512个3级表中的每个表都有512个条目),并且还有
- 512 * 512 * 512个1级表(每个2级表都有512个条目)。
页表格式
x86_64架构上的页表基本上是具有512个条目的数组。使用Rust语法就是:
1 |
|
如repr属性所示,页表需要进行页对齐,即在4KiB边界上对齐。此要求确保页表恰好能填满一页,同时允许优化以使条目更紧凑。
每个条目的大小为8个字节(64位),并具有以下格式:
| 位 | 名称 | 说明 |
|---|---|---|
| 0 | present | 本页是否存在于内存中 |
| 1 | writable | 本页是否可写 |
| 2 | user accessible | 如果未设置,则只有内核模式的代码可以访问本页 |
| 3 | write through caching | 对本页的写入是否能够直接进入内存,而无需经过缓存 |
| 4 | disable cache | 本页不使用缓存 |
| 5 | accessed | 当本页正在使用中,CPU将自动设置此位 |
| 6 | dirty | 当本页正被写入时,CPU将自动设置此位 |
| 7 | huge page/null | 此位在1级和4级页表中必须置为0,置为1时,在3级页表中会创建1GiB的页面,在2级页表中会创建2MiB的页面 |
| 8 | global | 地址空间切换时,本页不会被换出缓存 (必须将CR4寄存器的PGE位置为1) |
| 9-11 | available | 此位供OS自由使用 |
| 12-51 | physical address | 页面对齐52位物理地址的帧地址或下一个页表的地址 |
| 52-62 | available | 此位供OS自由使用 |
| 63 | no execute | 禁止将本页数据当做代码执行(必须将EFER寄存器中的NXE位置为1) |
我们看到只有第12-51位用于存储物理帧地址,其余位用作标志或由操作系统自由使用。这是可行的,因为我们总是指向一个4096字节对齐的地址,这可能指向一个页面对齐的页表,也可能指向映射帧的开头。这意味着位0-11始终为零,也没必要存储这些位,因为硬件会在使用地址之前将它们设置为零。第52-63位同样如此,因为x86_64架构仅支持52位物理地址(类似于它仅支持48位虚拟地址的方式)。
让我们仔细看看可用的标志:
present标志将被映射页面与未被映射页面区别开来。当主内存已满时,它可用于临时将页面换出到磁盘。当随后访问到该页面时,将会发生称为页面错误的特殊异常,操作系统将对此做出反应——从磁盘重新加载缺失的页面——然后继续执行程序。writable和no execute标志分别控制页面的内容是可写,还是包含可执行指令。- 当对页面被读取或写入时,CPU会自动设置
accessed或dirty标志。该信息可以被操作系统利用,例如,在决定换出哪些页面时,或者确定自上次保存到磁盘以来内容是否已被修改。 write through caching和disable cache标志允许控制每个页面的缓存。user accessible标志使页面可用于用户空间代码,否则仅当CPU处于内核模式时才可被访问。该特性使得CPU可以在运行用户空间程序时保持内核映射,该功能用于加快系统调用的速度。但是,Spectre漏洞仍然能够允许用户空间程序读取这些页面。global标志向硬件发出信号,表明该页在所有地址空间中都可用,因此不需要在地址空间切换时将其从转换缓存中删除(请参阅下文中有关TLB的部分)。该标志通常与被置为0的user accessible标志一起使用,用以将内核代码映射到所有地址空间。huge page标志允许通过使2级或3级页表的条目直接指向映射的帧,来创建更大尺寸的页面。设置此位后,对于第2级条目,页面大小将增加512倍,达到2MiB = 512 * 4KiB,对于第3级条目,甚至能够达到1GiB = 512 * 2MiB。使用较大页面的优点是需要更少的地址转换缓存行和更少的页表。
x86_64crate提供了页表及其条目的类型,因此我们不需要自己创建这些结构。
转换后备缓冲区
4级页表使虚拟地址的转换变得耗时,因为每次转换都需要4次内存访问。为了提高性能,x86_64架构将最后的几个转换缓存在所谓的转换后备缓冲区(TLB)中。当转换仍被缓存时,这允许跳过转换。
与其他CPU缓存不同,TLB不是完全透明的,而且在页表内容更改时也不会更新或删除转换。这意味着,每当内核修改页面表时,都必须手动更新TLB。为此,有一条特殊的CPU指令叫做invlpg(即“无效页面”),该指令从TLB中删除指定页面的转换,以便在下次访问时再次从页表中加载该转换。也可以通过重新加载CR3寄存器来模拟地址空间切换,从而完全清空TLB。x86_64crate为tlb模块为这两种更新方法都提供了Rust函数。
需要注意的是,在每次页表被修改时都需要刷新TLB,这一点很重要,否则CPU可能会继续使用旧的转换,这可能会导致难以调试的错误。
实现
有一个事实还没有提及:我们的内核已经在分页上运行了。在“最小化Rust内核”一文中添加的bootloader已经建立了一个4级分页层次结构,将内核的每个页面映射到一个物理帧。bootloader执行此操作是因为分页在x86_64的64位模式下是强制的。
这意味着我们在内核中使用的每个内存地址都是一个虚拟地址。我们之所以可以访问VGA缓冲区地址0xb8000,就是因为bootloader对该页面进行了恒等映射,即将虚拟页面0xb8000映射至物理帧0xb8000。
分页使我们的内核已经相对安全,因为每次超出范围的内存访问都会导致页面错误异常,而不是写入随机物理内存。bootloader甚至为每个页面设置了正确的访问权限,这意味着只有包含代码的页面才是可执行的,只有包含数据的页面才是可写的。
页面错误
让我们尝试通过访问内核外的某些内存来诱发页面错误。首先,创建一个页面错误处理程序并将其注册到IDT中,以便我们看到一个页面错误异常,而不是一个通用的双重故障:
1 | lazy_static! { |
CPU会在发生页面错误时自动设置CR2寄存器,其中包含导致页面错误的访问的虚拟地址。我们使用x86_64crate的Cr2::read函数读取和打印该虚拟地址。PageFaultErrorCode类能够提供关于诱发页面错误的内存访问的类型的更多信息,例如,该错误是由读取还是写入操作引起的。因此,我们也应打印该信息。不过,不能在不解决页面错误的情况下继续执行程序,因此我们在最后添加一个hlt_loop。
现在我们可以尝试访问内核外的一些内存:
1 |
|
运行内核,可以看到页面错误处理程序被调用:
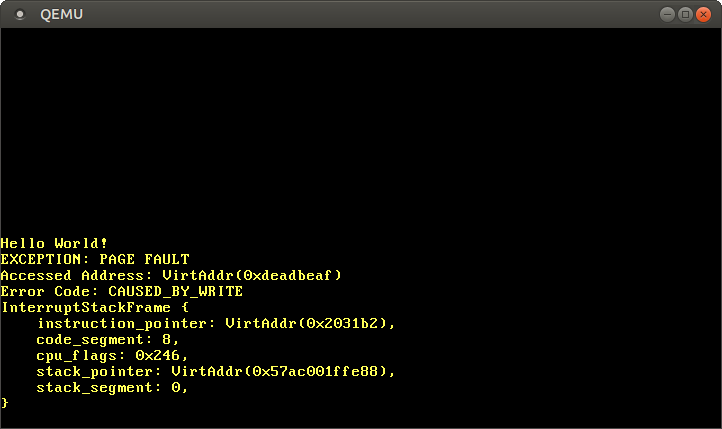
CR2寄存器确实包含了0xdeadbeaf,也就是我们尝试访问的地址。错误代码通过CAUSED_BY_WRITE告诉我们,尝试执行写操作时发生了错误。通过未设置的位,我们还能了解更多信息。例如,PROTECTION_VIOLATION位未设置,意味着由于目标页面不存在而导致了页面错误。
我们看到当前指令指针是0x2031b2,因此我们知道该地址指向代码页。bootloader将代码页映射为只读,因此从该地址读取是允许的,但写入会导致页面错误。您可以通过将0xdeadbeaf指针更改为0x2031b2来尝试此操作:
1 | // 注意:代码中的地址可能与你实际运行中得到的地址不同, |
可以看到读取访问有效,但是写入访问导致页面错误:
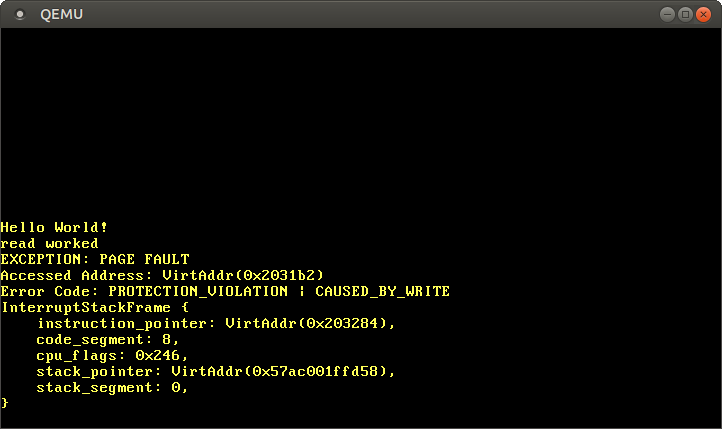
我们看到了“read worked”,这表明读操作没有引起任何错误。但是,并没有看到“write worked”,就发生页面错误。这次除了设置了CAUSED_BY_WRITE标志外,还设置了PROTECTION_VIOLATION标志,该标志说明被访问的页面存在,但对该页面进行的操作却并不被允许。在上面的例子中,由于代码页被映射为只读,因此对该页进行的写操作不会被允许。
访问页表
尝试观察一下定义我们内核如何进行映射的页表:
1 |
|
x86_64中的Cr3::read函数返回CR3寄存器中的当前活动的4级页表。函数返回一个由PhysFrame和Cr3Flags类型组成的元组。 我们只对这个帧感兴趣,于是忽略了元组的第二个元素。
运行后可以看到以下输出:
1 | Level 4 page table at: PhysAddr(0x1000) |
所以当前活动的第4级页表存储在物理内存的0x1000中,如其封装类型PhysAddr所示。现在的问题是:如何从内核访问该表?
当分页处于活动状态时,无法直接访问物理内存,不然的话程序将很容易避开内存保护去访问其他程序的内存。因此,访问该表的唯一方法是通过某些虚拟页面,该虚拟页面映射到地址为0x1000的物理帧。为页表帧创建映射这个问题是个普遍的问题,因为内核需要定期访问页面表,例如在为新线程分配栈时。
在下一篇文章中将详细说明该问题的解决方案。
小结
本文介绍了两种内存保护技术:分段和分页。前者使用可变大小的内存区域但存在外部碎片的问题,而后者使用固定大小的页面同时允许对访问权限进行更细粒度的控制。
分页将页面的映射信息存储在具有一计或多级页表中。x86_64架构使用4级页表,页面大小为4KiB。硬件会自动遍历页表,并将生成的地址转换缓存在转换后备缓冲区(TLB)中。此缓冲区不是透明更新的,需要在页表更改时手动刷新。
我们了解到现在的内核已经在内存分页上运行了,而且非法的内存访问将会导致页面错误异常。我们试图访问当前活动的页表,但是由于CR3寄存器存储了我们无法直接从内核直接访问到的物理地址,所以我们并不能执行此操作。
下期预告
下一篇文章将解释如何在内核中实现对分页的支持,并提供从内核访问物理内存的不同方法,这使得访问内核运行中的页表成为可能。至此,我们能够实现将虚拟地址转换为物理地址并在页表中创建新映射的功能。
支持本项目
创建和维护这个博客和相关库是一项繁重的工作,但我真的很喜欢。通过支持我,您可以让我在新内容、新功能和持续维护上投入更多时间。
支持我的最好方式是在GitHub上赞助我,因为他们不收取任何中间费用。如果你喜欢其他平台,我也有Patreon和Donorbox账户。后者是最灵活的,因为它支持多种货币和一次性捐款。
感谢您的支持!

